
Pythonでスクレイピングに挑戦です
これが意外と少ないコードで実現できました
コーディングのルールやライブラリが掴めてくると、
あっという間に自分の欲しい情報を自動で取得できるようなプログラムが作れそうです
今回は、私が車好きというだけの理由で
カーセンサーさんのサイトから車の情報を取得するスクレイピングコードを作ってみました
前提
バージョン:Python3(インストールは完了している前提)
マシン:Mac
今回紹介するコードで取得できる情報はこちら
% python sample.py レクサス - IS - 300 レクサス - IS - 300 Fスポーツ レクサス - IS - 300 Fスポーツ モード ブラックIII レクサス - IS - 300 バージョンL レクサス - IS - 300h レクサス - IS - 300h 4WD レクサス - IS - 300h Fスポーツ レクサス - IS - 300h Fスポーツ 4WD レクサス - IS - 300h Fスポーツ モード ブラックIII レクサス - IS - 300h Fスポーツ モード ブラックIII 4WD レクサス - IS - 300h バージョンL レクサス - IS - 300h バージョンL 4WD レクサス - IS - 350 Fスポーツ レクサス - IS - 350 Fスポーツ モード ブラックIII レクサス - IS - 500 Fスポーツ パフォーマンス ファースト エディション レクサス - LS - 500 Fスポーツ レクサス - LS - 500 Fスポーツ 4WD レクサス - LS - 500 Iパッケージ レクサス - LS - 500 Iパッケージ 4WD レクサス - LS - 500 エグゼクティブ レクサス - LS - 500 エグゼクティブ 4WD レクサス - LS - 500 バージョンL レクサス - LS - 500 バージョンL 4WD
このように、「ブランド – 車種名 – グレード」 の情報を一覧形式で取得します
今回は入門編として、コンソールにそのまま取得結果を出力していますが
CSV形式等で保存すればExcelで加工したり、他のシステムに取り込むこともできますね
ソースコード
# carsensorから車種情報を取得する
import re
import requests
from bs4 import BeautifulSoup
def getLinks(host) :
r = requests.get(host + "/catalog/search/#JPN")
soup = BeautifulSoup(r.content, "html.parser")
return [{'bland': url.next.text, 'url': url.get('href')}
for url in soup.select('div.country_wrap a')]
def getDetails(link, carsLinks) :
# 車種の詳細情報を取得する
for detail in carsLinks:
r3 = requests.get(host + detail['url'])
soup3 = BeautifulSoup(r3.content, "html.parser")
# 車種のグレード一覧を取得する
grades = [label.text for label in soup3.select(
'th.js_grade_name label') if label.text != '']
for grade in grades:
print(link['bland'] + ' - ' + detail['name'] + ' - ' + grade)
def getCars(links) :
for link in links:
# メーカー毎に車種一覧を取得
r2 = requests.get(host + link['url'])
soup2 = BeautifulSoup(r2.content, "html.parser")
# 車種とリンクを同時に取得
carsLinks = [{'name': url.text, 'url': url.get('href')}
for url in soup2.select('p.shashuListItem__shashu a')]
getDetails(link, carsLinks)
# carsensorのホストURLを定義しておく
host = "https://www.carsensor.net"
links = getLinks(host)
getCars(links)解説
getLinks
def getLinks(host) :
r = requests.get(host + “/catalog/search/#JPN”)
soup = BeautifulSoup(r.content, “html.parser”)
return [{‘bland’: url.next.text, ‘url’: url.get(‘href’)}
for url in soup.select(‘div.country_wrap a’)]requests.get(URL) によって、指定したURLへHTTPリクエストを送信します
r.content は↑のリクエスト応答のHTMLコンテンツを取得しています
これを加工可能な形にパース(変換)しているのが3行目になります
5行目に ‘div.country_wrap a’ という指定があります
こちらは実際にカーセンサーの画面を見た方が分かりやすいです
↓は各国の自動車メーカーが一覧表示されています
先程のソースの2行目にあった /catalog/search/#JPN は日本の自動車メーカーの
表示にフォーカスするURLになります
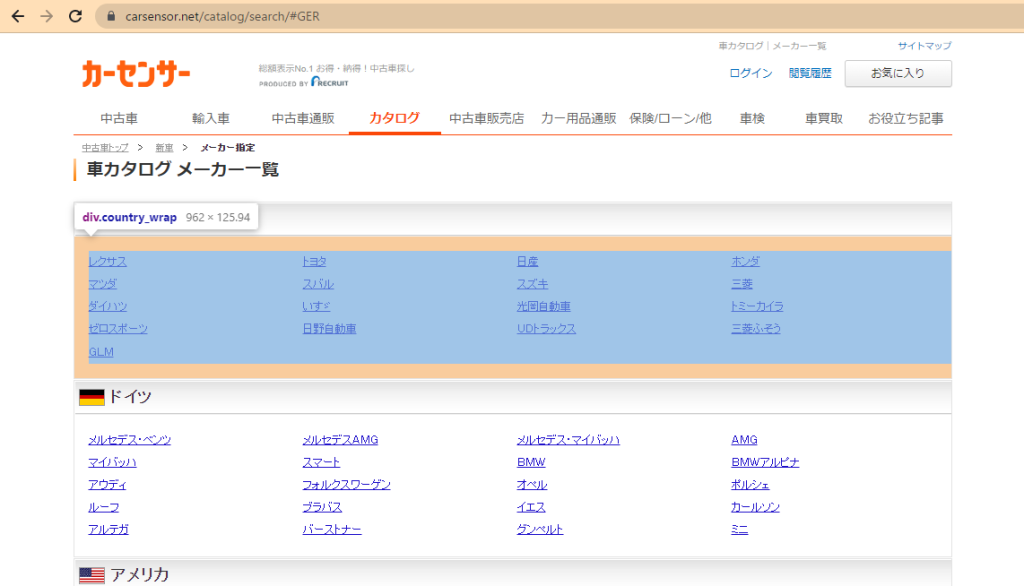
↑の画像で、日本のメーカーが括られている表示になっていますね
この各国のメーカーを括っているのが div.country_wrap になります
5行目にあった 'div.country_wrap a' はこの枠の中の a(アンカータグ) を取得する
という意味になります
for url in soup.select(‘div.country_wrap a’) の部分は各アンカータグの情報を
urlという変数に格納しています
{‘bland’: url.next.text, ‘url’: url.get(‘href’)} では
1. url.next.text によって(アンカータグの隣に表示されている)メーカー名
2. url.get('href') によってリンク
を取得しています
getCars
def getCars(links) :
for link in links:
# メーカー毎に車種一覧を取得
r2 = requests.get(host + link['url'])
soup2 = BeautifulSoup(r2.content, "html.parser")
# 車種とリンクを同時に取得
carsLinks = [{'name': url.text, 'url': url.get('href')}
for url in soup2.select('p.shashuListItem__shashu a')]
getDetails(link, carsLinks)先程のgetLinksで取得したリンク情報を受け取ってメーカー配下にある車種の一覧を取得します
getLinksと同様に、HTMLを取得→パースして目的の要素を取得するという流れになります
この処理ではパースしたHTMLソースから 'p.shashuListItem__shashu a' というタグを取得して
getDetailsへ引き渡しています
getDetails
def getDetails(link, carsLinks) :
# 車種の詳細情報を取得する
for detail in carsLinks:
r3 = requests.get(host + detail['url'])
soup3 = BeautifulSoup(r3.content, "html.parser")
# 車種のグレード一覧を取得する
grades = [label.text for label in soup3.select(
'th.js_grade_name label') if label.text != '']
for grade in grades:
print(link['bland'] + ' - ' + detail['name'] + ' - ' + grade)getCarsで取得した各車種のリンクを使って requests.get を実行し
取得結果をパース
車種のグレード一覧からグレードの名称を取得して
最後に print() 関数によってメーカー、車種、グレードを出力しています
使用しているライブラリ
今回使ったライブラリのご紹介をしておきます
re
Python標準のライブラリ、何もinstallせずに使用できました
正規表現でURLに特定の文字列を含むか判定する為にimportしました
re.match("^/catalog/.+", item['url'])例)re.match(‘正規表現’, 検査対象)
Requests
同期処理でhttpリクエストを発行するライブラリ
これを使うためにはインストールが必要で、下記コマンドでインストールできます
$ pip install requestsRequestsは同期処理なので結果を取得するまで待ち続けます
取得結果が大規模なデータとなる場合は注意が必要です
今回は順々に情報を取得していく処理にしているので特に問題はありません
例)r = requests.get(‘URL’)
これでHTMLを取得できるので、パースして操作できるようにします
BeautifulSoupに続く
BeautifulSoup
こちらもインストールが必要になります
$ pip install beautifulsoup4これで準備OKです
早速使います
例)soup = BeautifulSoup(r.content, “html.parser”)
r.content の部分によって HTML を取得できます
他にもヘッダ情報等も取得できるみたいですが、
今回やりたいことには関係ないので、スルーしています
soupという変数にパース(変換)されたHTMLが入っているので、
この中から欲しい情報を抽出します
例)soup.select(‘div.hogehoge’)
この記述でCSSセレクタのような事ができます
上の例だとdivタグのclassがhogehogeの要素が取得できます<div class="hogehoge" ></div>
このようにして自分の欲しい情報を抽出しました
いくらでも応用できる!
こんなざっくりな理解でも 「メーカー – 車種名 – グレード」 という情報を
リストで出力できるようになりました。
基礎知識はまだまだ足りずとも
にわか知識でこれだけ形にできると
手応えを感じられるのではないでしょうか
最初の形にするまで苦労する言語学習において
この敷居の低さはメリット大だと思います
これを読んだあなたはもうPythonスタートできますよ!

